LLMO対策とは?AI検索で上位引用を取る方法…実はSEOと同じ

ここ半年くらいのスパンで見た時、ChatGPTをはじめとする生成AIの勢いが凄まじいですよね。
以前はITの知識がある人たちが主に注目している印象だった生成AIですが、今では一般の20代女性でもGeminiで人生相談をしながら楽しんでいる様子を見るまでになってきました。
このようにAIがマスアダプションするにつれて、これまで多くの企業が投資してきた「SEO」が占めるリード獲得のパイは、SNSが台頭してきたときと同じように、AI検索にも流れていきます。
そこで今回は、AI×SEOの領域に注力している弊社アネマが、現時点で把握できているAI検索対策(LLMO)について共有します。
LLMOとは?
LLMO(Large Language Model Optimization)とは、ChatGPTやGeminiなどの大規模言語モデル(LLM)が生成する回答において、自社のコンテンツやサービスが引用されやすくなるように最適化する施策のことです。
従来のSEOはGoogle検索での順位を上げることが目的でしたが、LLMOは「AIが生成する回答に、自社が登場すること」をゴールとします。
これにより、ユーザーがAIチャットで質問した際、自社の商品やサイトが自然に紹介される確率が高まります。
LLMOはまだ発展途上の分野ですが、既に多くのAIが検索エンジンをベースに情報を選んでいるため、SEOがそのまま応用できる部分も多くあります。
なお、この記事のタイトルは検索需要に応えてLLMO”対策”と表記しましたが、そもそもLLM”O”の”O”がOptimization=最適化」なので、LLMO”対策”という言葉はおかしいです。これはSEO”対策”も同じです。
なので、弊社としてはSEO”対策”、LLMO”対策”という言葉を使用しないようにしています。
※2025年7月2日追記
日本のSEO事業者の中で最も早い段階、2025年2月にこの原稿を作成していた時点では、レンタルビデオショップの「ゲオ」と重複させたくなかったのでahrefs海外版の利用に揃えて「LLMO」表記を普及させようと考えました。一方で、時間の経過とともに海外では「GEO(Generative Engine Optimization)の方が主流となっていますので、2025年6月以降の発信において私たちは「GEO」表記を使っております。
この考え方に至った経緯や最新のGEO、AIO(AI Overview, AIによる概要)への対応策については、下記の動画で詳しくお話ししていますので、ぜひご覧ください。AIによる概要向けの動画ではありますが、GEOにも通じる話も多くしています。
この辺りを前置きとした上で、本記事では、LLMOについて見解を共有します。
LLMOを考える上でのポイント
まず従来のSEOは、検索エンジンの中でGoogleが一強だったことから、いわゆる“Google最適化”に集中する形でよかったですよね。
しかし、AI検索ではChatGPTだけでなく、GeminiやPerplexityなど、複数のプラットフォームがあります。
現時点ではChatGPTが一番シェアを持っていますが、Geminiも後発にも関わらず2位まで伸びてきていますので、今後もっと拮抗してくるかもしれません。
さらに、アメリカ・インドでは検索結果全体にAIによる回答生成がなされる「AI モード」が導入されています。※「AIモード」ではなく、スペースが入る「AI モード」が正しい表記
AI モードはまだ日本には導入されていませんが、ChatGPTが登場しても多くのユーザーはGoogleを活用しているという事実を踏まえると、AI モードはChatGPTよりも多くのユーザーに使われるということになるでしょう。※2025年9月23日追記:日本語版AI モードも現在は公開されています
そう考えると、AI検索対策(LLMO)を考えるとき、基本的にはAIモード最適化、あるいはChatGPT最適化を考えるのがベストです。
AI モード最適化は以前の記事で扱っていますので、今回はChatGPTとその他のAI検索ツールへの最適化でできることをメインに考えていきたいと思います。
» 【10本の青リンクが消える?!】Googleの”AI モード”と対応策について考えました
それぞれのAI検索ツールの違いを理解しつつ、主要なマスを取っていくように対策することが、今後のAI検索対策において重要になってくると考えます。
AI検索ツールからのサイト流入はどれくらいあるのか
現状、代表的なAI検索ツールを挙げると
- ChatGPT
- GoogleのAI Overview(AIによる概要)
- Copilot
- Perplexity
- Felo
- Genspark
- Grok
などがあります。
2024年時点でのユーザー利用率を見ると、ChatGPTが他を大きくリードしており、続いてGemini、PerplexityやCopilotは利用率が非常に小さい状況です。
私の方でも、GA4で「集客 → ユーザー獲得 → 参照元/メディア」でAI検索ツールからの流入を分析していますが、2024年11月の時点ではほぼ流入はなし、12月に数件程度、そして1月には12月の3倍ほど増加するもまぁほぼ無視できる程度、2月にはChatGPTからコンバージョン(CV)が出始めたという状況を目にしています。
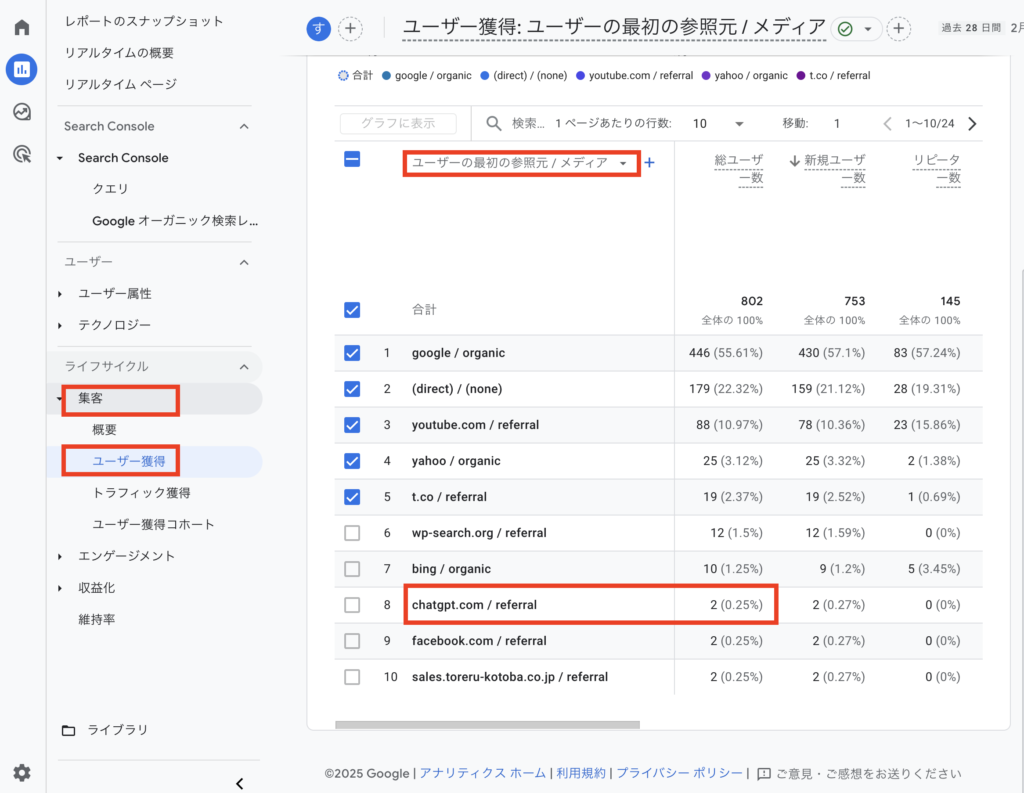
もっとも、2025年2〜3月時点でも、AI関連ジャンル以外のサイトでは全体の1%にも満たない程度に見えます。
2024年2月に海外のKEVIN INDIG氏が公表したレポートでも、AIチャットボット経由のWEBサイト訪問は全体の0.17%程度だったとのことで、海外でもまだまだ少ないのが実情です。
しかし国内でも、AI関連ジャンルにおいては利用者がAI検索エンジンを積極的に使うため、キーワード単位で流入シェアが10%ほどになっているケースも報告されていました。
先ほどのINDIG氏のレポートでは、「63%のWEBサイトが何らかのAI経由のトラフィックを受け取っている」ことや、「サイトの上位層ではAIからの訪問が全体の最大6%に達する」という例も出ています。
要するに、先進的なキーワード領域ではAI検索流入が増加しており、今後はさまざまな業界にも広がっていくはずです。
ただ、2025年2月時点では通常のSEOのほうが圧倒的に流入が多いので、AI検索対策で慌てるよりは既存のSEOの方が重要だと言えます。
一方で、2024年11月にOpenAIがChatGPTの検索機能(ChatGPT search)を有料ユーザー向けに公開し、12月に無料ユーザーにも拡大したことで、ChatGPT経由の流入は増えているはずです。
そういう機能追加を知らなかった方々もどんどん使っていると思われるので、半年後には今よりももっとLLMOの重要度が高まるはずです。
各AI検索ツールはどの検索エンジンを参考にしているのか
ChatGPTはBingベース
ChatGPTは、Microsoft Build 2023で公式発表があった通り、Microsoft BingのAPIを利用しています。
そのため、引用されるページや順位付けの考え方はBing検索に準じることが多いです。
Bingの検索順位とGoogleの順位は異なることを前提として知っておく必要があり、Bingで上位表示されているサイトがChatGPTでも引用されやすいです。
ただし、Bingの検索インデックスをそのまま使うのではなく、弊社で分析する限りではフィルタリングを行なっているようなので、実際のGPT引用ではBingそのままではなく、Googleのように公式サイト・権威サイトが重視される傾向があると考えています。
※2025年7月7日追記
まだ確定情報ではないのですが、ChatGPTのWEBブラウジング時に使っている検索エンジンがBing→Googleに変更されている可能性が出てきました。私が感じていた「フィルタリングの影響でGoogleのようになっている」ではなく、そもそもGoogleだった可能性があります。そうすると、よりGEO(LLMO)≒SEOとなります。
AI モード(AI mode)はGoogle
GoogleのAI モードは、まずGoogleの検索エンジンを使っています。
さらに、Googleが独自に持っている大きな知識のデータベース(ナレッジグラフ)も利用できるので、普通のAI検索よりも「E-E-A-T」という基準(経験・専門性・権威性・信頼性)をしっかり理解できるのが強みです。
また、Googleの検索結果は、有名な企業や公式サイト、専門的なメディアなどが上位に出やすい傾向があります。
そのため、小さな規模のブログなどは、検索結果の上位にあまり表示されにくいという特徴があります。
CopilotはBing
次にCopilotについてです。
Windows 11(ウィンドウズ・イレブン)やMicrosoft Edgeに組み込まれたMicrosoft Copilotも、Bing検索をベースに情報取得しているため、Bingでの上位表示がそのまま引用に繋がりやすいです。
PerplexityはGoogle寄り
PerplexityのCEOであるAravind Srinivas(アラヴィンド・スリニヴァス)氏は、GoogleとBingの両方の検索データを組み合わせていると公言しています。が、実際には提示される情報源がGoogle検索結果と類似するケースが多いと言われています。
Perplexityは独自クローラ(PerplexityBot)でサイトを収集し、さらにGoogleとBingの検索ランキング情報を組み合わせて回答を生成する仕組みです。
面白いのは、アフィリエイト色が強いブログでも“内容が的確であれば”引用される傾向がある点で、Googleがあまり高く評価しない商業寄りの記事でも質が高ければ参照するケースが見られるようです。
このためニッチな専門サイトでも、網羅性や有用性が高いと判断されれば引用のチャンスがあると言えます。
Felo→独自
Felo AI Searchは日本市場向けに最適化された独自のアルゴリズムを採用しているそうで、Yahoo! Japanなど国内の情報も含めて評価している可能性があるといわれています。
日本語の質問でも他言語情報を収集し、日本語で回答を生成する、多言語対応に優れた国産AI検索エンジンです。
SNSからの最新情報抽出にも対応しており、X(旧Twitter)からのトレンド情報を回答に反映させることもできるようです。
Felo公式がXで言及したところによると、SEOの順位をそのまま参考にするのではなく、ページのアクセス数や滞在時間などのユーザー行動データを重視しているとのこと。

つまり、GoogleやBingの上位ページをそのまま引っ張るのではなく、独自のページ評価データをもとに引用を決定する仕組みがあるようです。
Genspark→独自
Gensparkは質問に対し少数の主要サイトを深く参照する傾向があります。
BingのAPIなどを下地にしつつ、独自のクローラで補完するハイブリッド型と言われています。
GoogleやBing上位の包括的な記事を核にして、関連サイトをいくつかピックアップして独自の要約ページを生成するという動きが見られます。
また、「広告やSEOのバイアスが少ない情報収集」を謳っており、単なる検索結果そのままではなく、自社基準での取捨選択を行っているようです。
こうしたツールそれぞれに違いはあるものの、ベースはBingかGoogleである場合がほとんど。
GoogleでSEOをやっているなら一通りカバーはできますが、ChatGPT(Bing)を利用している人も多いので、Bing対策も把握して損はないと言えます。
Bing検索対策のポイント
ChatGPTで上位表示(引用)を狙うなら、Bing検索の探求をしていきたいです。
ここでは、Google検索との違いを簡単に挙げていきます。
Bingはよりキーワードマッチ
BingはGoogleより「キーワードが一致するかどうか」を重視する傾向があると言われています。
検索エンジンは、検索クエリ(検索する言葉)の「意味」や「文脈」の理解に大きな重点を置いています。
GoogleもBingも「ナレッジグラフ」という構造化データベースを持っており、「ある言葉(エンティティ)が何を指しているのか」を深く理解し、関係する情報を幅広く結びつけて理解しています。
「エンティティ」というは、人物・場所・モノなどの概念のことです。
[シャー 動物]と調べた時にGoogleでもBingでも「威嚇のこと。猫のシャーは威嚇です。」みたいに出てくるのですが、それは「威嚇」という概念を理解できている証拠です。
私も自分でGoogleとBingで検索を比較してて、Bingもエンティティ同士のつながりであるナレッジグラフを細かく持っていると思うのですが、GoogleがE-E-A-Tのサイトの評価をより検索順位に組み込むので、そう言われちゃうのかなと思いました。
例えば、先ほどの[シャー 動物]というキーワードの検索結果の例だと、Googleは動物病院やX、アメブロ、YouTube、note、Yahoo!ニュースといったドメイン強めの記事が上位に上がってきていて、Bingだとペット特化サイトが上位に上がってくる違いがありました。
別の角度でいうと、Googleは同じ会社が運営している別の発信源(YouTubeやX)からも発信主のエンティティが同じだからか積極的に出しますが、Bingはあまり出てきません。
また、Googleではスパムが悪用するのでもはや見ていない「meta keywordタグ」を、Bingはある程度参照しているとも言われます。
被リンクやソーシャルシグナル、コンテンツの理解にも違いがある
その他、被リンクやソーシャルシグナル、コンテンツの理解に若干の違いがあると言われます。
被リンクの観点では、Googleは量と質(量は被リンクの数で質はより被リンクを多く集めているサイトかどうかです)、量と質の両方を強く重視しますが、Bingは質の高い被リンクを特に評価する傾向があるということです。
数の程度でどの程度違うのかは検証できていませんが、検索結果を見る限りahrefsのDR(ドメインの量と質を100段階評価した数値)はBingよりもGoogleの方が高いです。
例えば先ほどの[シャー 動物]もそうですし、違うジャンルで[ガンプラ 作り方]と調べてもBingは個人運営のサイトが上位にくるのに対してGoogleでは電撃ホビーウェブやバンダイ ホビーサイト、noteなどのサイトが上位にくるので被リンクは全然違います。質・量の問題というよりもそもそも内容よりもドメイン重視に見えます。
ドメインあっての内容というのがGoogleというか。
後は細かいところでは、BingはGoogleよりも
- 内部リンクで、アンカーテキストとコンテンツの関連性が高い場合をより評価
- 政府系ドメインからのリンクやドメインの運用歴も評価材料になる
- ソーシャルシグナルもランキング要因として見ている
- Bingは画像や動画などのマルチメディアコンテンツを理解するのが得意で、見た目がリッチなサイトを好む、一方のGoogleはテキスト解析が主体
- BingはGoogleほど高頻度でクロールせず、主要ページを重点的にインデックスするという方針
みたいな話があります。
政府系ドメインはどうなんでしょうか。
政府系ドメインばかり登録しているサイトで私が観測していたドメインがあり、そのサイトでGoogleにて上位表示しているキーワードがBingでどうか比較してみました。
Googleで負けているところは公式感、大手ドメイン感で負けていて、Bingでは勝っていた、Bingでそのサイトよりも下に表示されているサイトもドメインで勝っているというよりもコンテンツの質でそもそも勝っていたので、大して大きい話ではないと思います。
ソーシャルシグナルはX(Twitter)やFacebookなどで多くシェア・支持されているコンテンツが上位に来やすい可能性があるということですね。
この動画を撮っている前日に、「Notionから79万円の請求がきて寿命が縮んだ」というnoteの投稿がXでバズっていました。ソーシャルシグナルは十分にあると思います。
翌日3月17日にBingとGoogleそれぞれで[notion 請求]と検索したところ、Bingでは1ページ目に記事がありましたが、Googleではnoteの違う1年前の記事が上位に上がっていました。Googleでもインデックスはされていたので、Bingの方がソーシャルシグナル重視はあるかもしれません。もう少しサンプルを集めたいですね。
ただ、GoogleでもXなどで話題になると一時的にフワッと順位上昇が見られますが、数ヶ月単位の長い目では落ちる印象で、それとBingがどう違うのかは検証してみないといけないですね。
また、BingはGoogleほど高頻度でクロールしないという話があるのですが、昨日・今日でXでバズっていたWEBページは軒並みインデックスできていたので、そんなに酷くはないと思います。
心配であれば、「Bing Webmaster Tools」でサイトマップやURL送信をしておくといいでしょう。
まとめると、Googleにも評価されるべきサイトを作れて入れば、公式感、権威サイトであるという観点を除きBing対策にはなると思います。
Bingの検索順位を見るには
Bingの検索順位を見るには、GRCはBingの検索順位をデフォルトでチェックできますが、クラウド型のNobilistaの場合はデフォルト設定ではBing順位が見られません。
ただ、2024年8月の機能追加で、コストは2倍かかりますが設定すればBing順位も計測できるようになったので、必要に応じて設定しておくと便利でしょう。
LLMOの具体的な施策は?…実は既存のSEOと同じ
次に、基本的にはSEOでも重要で特にLLMOだから新しいというわけではないのですが、AI検索対策(LLMO)にも通じる対応施策について解説します。
この記事で一番大事なポイントとも言えますが、アウトプット先が検索エンジンかLLMかの違いなだけで、基本は従来のSEOを行うことがLLMへのベストプラクティスであることは勘違いしないでください。
「SEOで今まで負けてたけど、LLMOで一発逆転」←これはできないです。むしろ、SEOで評価されていたところがLLMにも評価されます。GoogleにもLLMにも評価されるだけの事業実態をつくりましょう。その上で、コーポレート部署と自社ブランドの保全・活用について擦り合わせた上で、各プラットフォームに最適な形で担当者から情報発信しましょう。
何度でも言いますが、「SEO終了!LLMO到来!」というのは完全に間違っています。共存しますし、情報源がWEBサイトで同じで、アウトプット先が検索エンジンかLLMかの違いなだけで、SEOで強いところが基本的にはLLMOでも強くなります。短期的なLLMO施策に大した意味はありません。GoogleやLLMが参照する「元情報」の強化を頑張りませんか?
SEO≠LLMOではなく、Google向けのSEO≒AIのSEOです。細かいところで違いはあります(海外から参照してくる、自社メディア以外も使う視点がいるなど)が、基本はSEOをちゃんとやり切れるところこそがLLMOでも成果を出せるところと認識しています。めちゃくちゃSEO考えている人がプラスアルファでAI向けを意識するのはありだと思いますが、既存のSEOで負けてるところをLLM向けで逆転というストーリーはないです…
「LLMOで一発逆転」ということはあり得ないです。SEOで勝っているところがLLMOでも勝つとご理解ください。
以下はどれも既存のSEO向けの施策ですが、LLMOにも通用するので共有します。
セマンティック検索を理解する
LLMの仕組みを理解することです。
まず、AIも検索エンジンもですが、「セマンティック検索」という技術で動いています。
これは、単純なキーワードの一致ではなく意味的な類似性に基づいて関連情報を検索する技術です。
ユーザーからのの質問を単語そのままではなく文脈や概念ベースで理解し、データベース中から関連性の高いテキスト片を見つけ出して回答を作っています。
また、LLMは自然言語から学習するのですが、この時キーワードとキーワードの結びつきを理解します。
専門的にいうと、「エンべディング」といって、学習するページの内容をベクトルという形に数値化しており、ベクトル間の距離を図ることで関連するトピック同士の結びつきを理解しています。
これが最重要で、WEB上での自社の発信や他社からのテキストを伴う言及が増えればLLMの学習時に「XX業界とYY社は近い」と理解できるので、LLMの回答から自社ブランドを紹介させることに一役買います。
LLMのカットオフの前までに学習できているか否かではありますが、任意の業界で会社名を大手から中小まで聞いて行った時に、回答できる会社とそうでない会社があるのはそのためです。
「任意の会社」のエンティティ(存在)を特定の業界というトピックに結びつけてWEB上に記録していく。この積み重ねがないとLLMから自社ブランドを言及させることができません。
これは、自社ブログを更新する以外にも、XやYouTubeなどのSNSを運用したり、広報でプレスリリース発信することもLLMOに一役買います。
» 【LLMO】AIに自社名をおすすめさせる方法を解説します
最新の情報を出す
LLMとセマンティック検索を組み合わせた仕組みがRAG(Retrieval-Augmented Generation)です。
LLMがRAGとして検索から回答をつくるにしても、後出しででてくる情報ほど正確性は増します(AIの情報なんかをイメージするとわかりやすいですね)。
ただし、新しい情報が必ずしもすべてのクエリで優先されるわけではありません。検索エンジンは被リンクや権威性なども考慮しているため、時事性が重要なクエリの場合に新しい情報が引き合いに出やすい、という点に留意しましょう。
そのため、古い記事よりも新しい情報の方が信頼性が高いので、引用されやすくなります。
※どのメディアから出ている情報なのか、被リンクや拡散はどれくらいされているかという別観点も重要です。
適切なHTML構造を意識する
適切なHTML構造を意識するということも役に立ちます。
これはSEOの超基礎でもあるのですが、ページのHTML構造を正しくマークアップすることで、AIにとっても情報を理解しやすくなります。具体的には、見出しタグ(h1、h2、h3など)の正しい階層構造、重複しないメタディスクリプションの設定、画像にはalt属性を付けるなど。
最も基本的で面白みはないと思いますが、正直これが一番大切だと考えています。
また、生成AIは現状、動画の内容を直接解析して引用するというより、動画の説明文やテキスト部分を主に参照しています。YouTubeのSEOも同様で、概要欄に重要なテキスト情報をまとめておくのが大事です。
情報の根拠をリンクさせる
5つ目は、根拠の明示をしっかりやりましょうということです。
コンテンツの中で公式データへのリンクや参考元を明示し、情報の信頼性を高めるということです。
正直、これをやっても「引用元がAIに引用されるだけなのでは」と一瞬思いましたが、引用元がAIに引用されるだけでなくじゃなくて、引用しているサイト自体もE-E-A-Tの観点で信頼性が明確であると評価されるので、結果サイトの信頼性が上がるといえます。
FAQ形式・Q&A形式のコンテンツを増やす
6つにはFAQ形式・Q&A形式のコンテンツを増やすということです。
ChatGPTやAI検索では、ユーザーが質問を入力し、その回答が提示される形式です。つまり、よくある質問と回答をペアにしたコンテンツとは相性が良いということ。
見出しに具体的な質問を入れ、その直下に200字前後のコンパクトな回答を用意するなど、構造を明確にしておくとAIに学習・引用してもらいやすくなります。
AIが生成する回答を定期的に監視する
AIに自社が出てきそうな質問をしてみて、生成する回答を定期的に監視するということも重要です。
ChatGPTなど主要AIに対して、定期的に「〇〇業界でおすすめのサービスは?」「△△(自社商品)の評判は?」などの質問を投げてみて、自社名が回答に入っているかをチェックしましょう。
もし競合が紹介されるのに自社が全く出てこない場合は、自社情報が学習データに十分含まれていない可能性があります。ブランディングの観点で、業界における認知度・専門性を高める情報発信を強化する必要があるわけです。
これは自社サイトだけ頑張ってもブランディングの観点では不足するので、他社サイトからも言及されるような活動をしていきたいですね。
例えば、WEB制作会社であれば、お客様がAIに「おすすめのWEB制作会社はどこ?」と聞いてしまう可能性があるので、WEB上でのサイテーション獲得は重要になります。
ちなみに、「おすすめのWEB制作会社はどこ?」とChatGPT、Gemini、Claudeに質問したら結構違う会社が上がってきました。
llms.txtは置かなくて良い
一点ポイントとして言えるのが、「llms.txtは置かなくてよい」というものです。
2024年9月にJeremy Howard(ジェレミー・ハワード)氏が提案したもので、日本でも3月頭にXで話題になっていたやり方です。robots.txtの設定で、llms.txtを配置するというもの。
これがAI向けのサイトマップのような役割を果たして、サイト内の重要なコンテンツやカテゴリーをLLMに伝えるのに役立つという「噂」があり、「LLMO対策方法!」のような形で広まってしまいました。
が、現時点では大手LLMや検索エンジンがこの仕組みを公式にサポートしているわけではありません。Googleも使用していないので入れる必要がありません。
llms.txt、外してからの方がむしろGPT流入比率2倍近くになりました(月が違う点は注意)。LLM各社が標準採用を宣言するか、またはサーバーログでGPTBotが頻繁に見られるようになるまでは、あんまり関係ない状態かと考えています。
構造化マークアップも、Googleにおけるエンティティの機械的な理解がより正確になりますが、GPTなどのLLMは標準採用してないです。AIモードには効果があり、GPTなどには効果ないかと。
まとめると、小手先なLLMOというものに、大きな効果はないかと考えます。
むしろ意味あるのはコーポレートブランディングで、アネマではエンティティ・ブランディングも含めたコーポレートブランディングに注力したいと思います。
LLMからの流入は、参照元がo3では海外ソース重視になることも見られてきたため、LLMO全体は対策できないが、自社のエンティティ(会社名、事業ブランド)を事業実態のある範囲で適切にブランディングする支援はできるかと思っています。
コーポレートブランディングの領域は新卒の頃からずっと携わってきましたので、ここにより注力していきます。
llms.txtの恩恵を受けるには、将来的にLLM側(検索エンジンやAIクローラー)がこの取り組みを採用・活用することが前提です。そのような動きがでてきたらYouTubeやXにて共有します。
構造化データを設定する
Google検索が推奨している構造化データマークアップ(schemaなど)も、将来的にChatGPTやClaudeなどが利用するようになる可能性もあります。
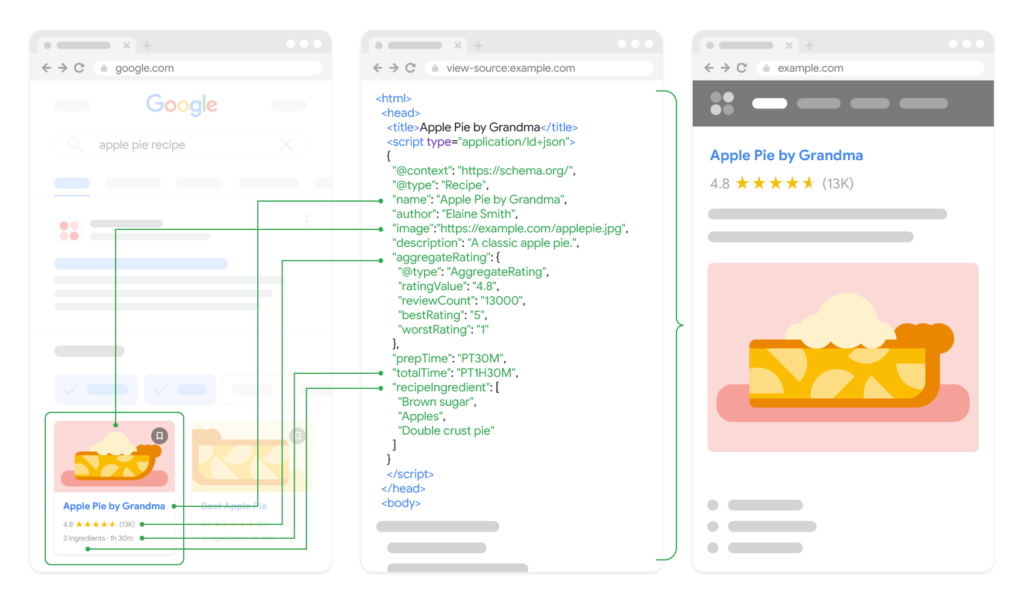
従来のHTMLマークアップに加えて、その単語や記述が何を意味しているかを明示する構造化マークアップを実装しておくことで、AIが理解しやすくなり、引用されやすくなるかもしれません。
もっとも、現時点ではChatGPTなどのGoogle/Bing以外のLLMがschema.orgマークアップを直接的に利用しているわけではないという見解が一般的です。
ChatGPTのモデル開発のための事前学習では自然言語でトレーニングされており、構造化マークアップを使う場面がありません。また、GPT searchなどにおいてもBingの検索インデックスを使用するものの基本は自然言語を使っています。
ただし、モデル開発時の学習元となるSEOの順位は構造化マークアップの影響があるので、間接的にはBingやGoogle経由で影響を受けているとは言えます。
また、構造化マークアップを使用すればより回答の精度を高められるので、LLMで構造化マークアップを使用する研究や期待はあります。
AI引用順位を分析する方法
従来のSERPs順位チェックと違い、AIの回答は質問内容やタイミングで変わってしまうため、AI引用順位のトラッキングは難しいです。とはいえ、いくつかのツールが登場し始めています。
Brand Rader
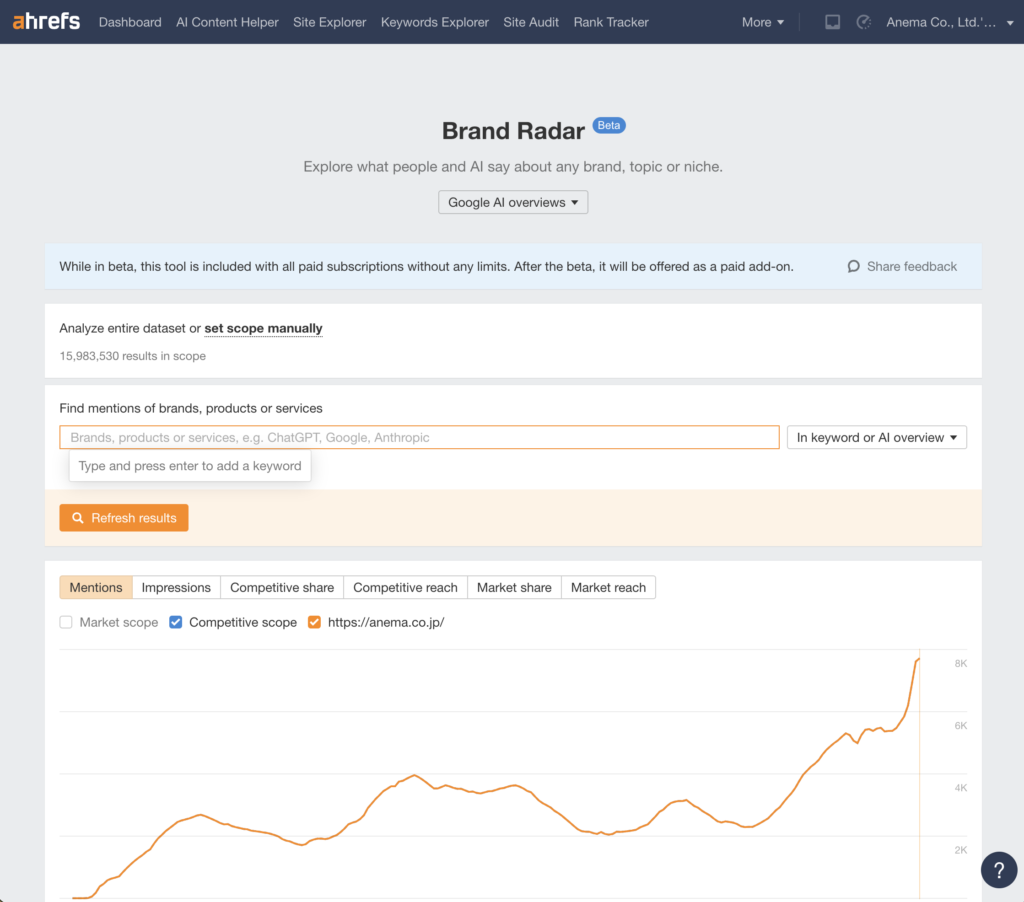
ahrefsの新機能で、AI Overviewでの言及数をドメイン単位で可視化できる機能が出ました。
今はベータ版です。ドメイン単位でのメンション数、インプレッション数などを数値でも見ることができます。
特に記事数増やしてなくても3月でどかーんと増えたので、3月のAIモード発表と合わせてAI Overviewの表示も増えているのかと思います。
他のツール
他、Chrome拡張機能でAI Overview流入を分析できるツールやPerplexity、ChatGPT、Google Gemini、Claude流入などを横断的に分析できるツールはあるのですが、使いやすそうには見えなかったので、今回は紹介なしにします。
数ヶ月も待っていれば出てくるはずなので、また追って紹介します。
ahrefsは有料ツールですが見やすいので紹介しました。
※2025年9月23日追記:アネマでは現在海外版のGEO分析ツールである”Profound”を契約しています。しかし、年間100万円近くのコストがかかってきますので、ほとんどの会社様には不要だと考えています。
身銭を切って海外製のAI検索分析ツールに課金していますが、正直どこもまだおすすめとは思わないです。我々SEO専業会社が検証するにはいいと思いますが、各事業会社さんが契約する場合は、よほど大規模でない限り、投資としてはコスパ悪いかと。課金する→痛いなぁ、課金する→痛いなぁを今繰り返しています。GA4と、実際に自分で狙っているクエリでAI検索していただく、で普通の方は良いと思います。
今見えているLLMOはこんな感じ。既存のSEOを大切にしましょう
今回は2025年2月時点(※一部9月時点の情報を補足)でリサーチして探求できたLLMOのノウハウを今日は皆様と共有しました
一口に「AI検索対策(LLMO)」といっても、ChatGPTはBingベース、GeminiはGoogleベースなど、裏側の検索エンジンが異なれば引用されるロジックも変わってきます。PerplexityやGenspark、Feloなどは独自クローラも加えて評価しているため、また別のクセがあるはずです。
現状(2025年2月)、AI系キーワード以外ではAI検索流入はSEOの1/100程度にすぎませんが、確実に増え始めています。
長期的にはAI検索での上位引用が重要性を増す可能性は大いにありますが、今はまだ従来のSEOのほうが圧倒的に大きな効果を見込めます。
そしてほとんどのAI検索ツールは既存の検索エンジン(GoogleやBing)のインデックスやランキングを活用しています。つまり、繰り返しですがアウトプット先が10本の青いリンクかLLMかというだけで、参考にできる情報もアルゴリズムで上位に出力される結果もほとんど同じになるということ。
まずは基本のSEOをしっかり固めることが何よりも大切です。
弊社ではAI×SEO領域でメディア運用体制構築の支援や方針策定なども行っています。
GEO、LLMOにおいては過度な煽りも多く、不安になっている企業からのご相談も多いです。弊社は特に押し売りしませんので、何かお困りでしたら、ぜひご相談ください。
» GEO(AI検索対策, 旧LLMO)についてお問い合わせ