【LLMO】AIに自社名をおすすめさせる方法を解説します

最近、ChatGPTをはじめとするAIに質問して情報を得ることが増えてきましたよね。
「LLMOとは」の記事でも扱いましたが、業種によっては2月ごろから運営されているメディアでCVが出始めたという方も多いのではないでしょうか。
もちろん、まだまだGoogle SEOからの流入やお問合せの方が多いので、既存のSEOが大事なのは大前提です。
とはいえ、これからAI検索を使う人はもっと増えていきます。今後よりAI検索からの流入も増えていきますので、またAIの影響について扱っていきます。
さて、今回は「LLMOで自社名を出すには?」というテーマで解説します。
「LLM」というのは、”GPT-4”のような、テキストを作ってくれるAIのことです。
皆さんChatGPTなどの生成AIを日常で使われていると思うのですが、今後今までGoogleで行っていたように「⚪︎⚪︎でおすすめな会社は?」とAIで調べる機会が増えると思います。
例えば、「岐阜県庁の近くで美味しい焼肉屋さんは?」とか。これをGoogleマップじゃなくて、AIに聞いちゃう、みたいな。
飲食店だけじゃなくて、「名古屋でおすすめのWEBデザイン会社は?」とか、ビジネスの場面でも使われるはずです。
そのため、今回お話しする「LLMOで自社名を出すには?」っていうのは、これからSEOで上位表示することや、Googleマップにお店を載せることと同じくらい、重要な投資になっていくはずです。
また、動画でも解説しているので、音で聞きたい方はぜひご活用ください。
弊社アネマでは、このようにSEOにおけるAI活用、LLMOへの対応策など、業界最先端のナレッジを動画で解説しながら現場への実装に対してもコンサルティングを行っています。
弊社の運用支援は下記よりお問い合わせください。
» SEOの分析・戦略についてアネマに相談する
それでは、本題に入っていきましょう。
【大前提】LLMOには種類がある
まず、大前提として知っておいてほしいのが、「LLMO」にはいくつか種類があるということです。
「LLMO」というのは、「LLM」、つまりテキストを作るAIに対して、最適化(Optimization)することです。SEOが実質的にGoogle検索への最適化だったのに対して、LLMOはAIへの最適化、と考えてください。
ただし、LLMという「モデルそのもの(GPT-3やGPT-4など)に対してSEOしていく」よりも、「LLMの回答に対してSEOする」という考え方の方が正確なので、私たちアネマでは現在AI検索対策のことを”GEO(Generative Engine Optimization)”と呼んでいます。今回は、日本における検索ニーズの都合上、”LLMO”表記で解説します。
そんなLLMOですが、いくつかパターンがあります。
LLMOの種類①:AI モード
1つ目は「AI モード(×:「AIモード」)」。これは、Googleがアメリカで試験的に始めたもので、2025年9月現在では国内においても日本語版が公開されています。
普段Googleで検索すると、青い文字のリンクが10個くらい並びますよね? あれが、AIが作った回答で画面が埋まる、というイメージです。
ただ、これは基本的にGoogleで上位表示されているページを元に作られるので、対策としては、今までのGoogle SEOがそのまま有効になります。
» AI モードについてはこちら
LLMOの種類②:LLM(Web検索なし)
2つ目が、「Web検索機能がついていないLLM」です。
「LLMO」と一言で言っても、ChatGPTの基本的なモデルのように、インターネットで最新情報を調べずに答えるAIと、Web検索ができるAIとでは、考え方が少し違います。
Web検索なしのAIは、インターネットにつながって検索してくれるわけではなく、開発された時点までに学習した情報だけで回答を作ります。
LLMOの種類③:LLM+RAG(Web検索あり)
3つ目が、「Web検索機能がついているLLM」です。ChatGPTの検索機能(GPT searchなど)がこれにあたります。
これは、AIがインターネット上の情報(Webページなど)を調べて、その情報をもとに回答してくれるモードです。回答と一緒に、参考にしたWebページへのリンクが表示されることもあります。
このWeb検索機能は、専門用語で「RAG(ラグ)」と呼ばれたりします。
さて、「LLMOで自社名を出すには?」という話に戻りますが、2つ目の「LLM(Web検索なし)」に、AIが学習する段階で自社の情報を覚えてもらうのと、 3つ目の「LLM+RAG(Web検索あり)」で、検索結果として自社を出してもらうのとでは、対策の考え方が変わってきます。
今回は主に、2つ目の「LLM(Web検索なし)」、つまり、AI自身にどうやって自社の情報を覚えてもらうか、という点にフォーカスしてお話ししたいと思います。
LLMOを理解するために、LLMの仕組みを把握する
LLMOを考える上で、まず「LLM」、つまり文章を作るAIがどうやって動いているのか、簡単に理解しておきましょう。
先ほどもお話しした通り、LLMはテキストを作るAIのことです。
でも、人間みたいに本当に「考えて」文章を作っているわけではありません。 あくまで、「この言葉の後には、こういう言葉が続きそうだぞ」と、文脈に合わせて確率的に、それっぽい文章を機械的に作っているだけなんです。
LLMは「次に来る言葉」を予測して文章を作っている
もう少しだけ言うと、AIは言葉の意味をそのまま理解しているわけじゃなくて、言葉と言葉の関係性を、数字のデータとして覚えています。
もう少し正確にいうと、AIは単語の意味はそのままでは理解しておらず、エンべディングという作業によりパラメータに落とし込んで概念を把握しています。
この関係性のデータを使って、「この単語とこの単語は関連が深いな」とか、「この文脈なら次はこの単語だろう」という感じで、次の文章を予測して生成しているんです。
※コサイン類似度で距離がわかります
ここで重要なのが、「文脈」です。
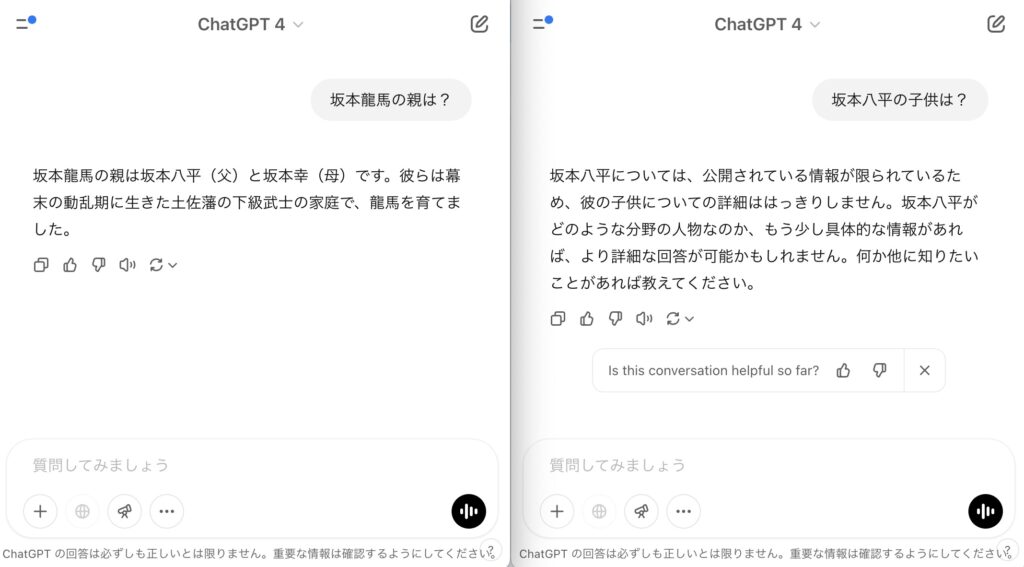
例えば、初期のGPTの頃、「坂本龍馬の親は?」と聞くと、「坂本八平(はちへい)だよ」と答えてくれました。このとき、別のチャットを立ち上げて、「坂本八平の子は?」と聞いても、八平が誰かわからないと言っていました。
今だと、4oなら自動でGPT search、o1なら持ち前の推論力で正しい回答をするのですが、以前のモデルでは、AIが「坂本龍馬の親は八平」という文脈では学習できているけど、「坂本八平の子は?」という文脈では学習できていなかったので正しい回答ができませんでした。
こうならないためには、名前とAIに回答させたい文脈をモデルに事前学習させていく必要があります。
自社とポジションをとりたいトピックの関連性を結びつける
LLMには知性があるわけではないので、ただ関係ないサイトからリンクを貼ってもらっても、LLMO対策としてはあまり意味がないです。
自社を知ってもらいたい分野・トピックと、自社名やブランド名が、ちゃんと関連付けられてWeb上でたくさん言及されている必要があります。これがLLMOで最も重要な考え方です。「llms.txt」みたいな設定ファイルを入れたらOK、という単純な話ではないんですね。
ちなみに、最新モデルのAIが賢くなったのは、初期とは比較にならない大量のテキストで事前学習したからです。「スケーリング則」という法則があって、学習するデータ量が多ければ多いほど、AIの性能が劇的に上がるんですね。
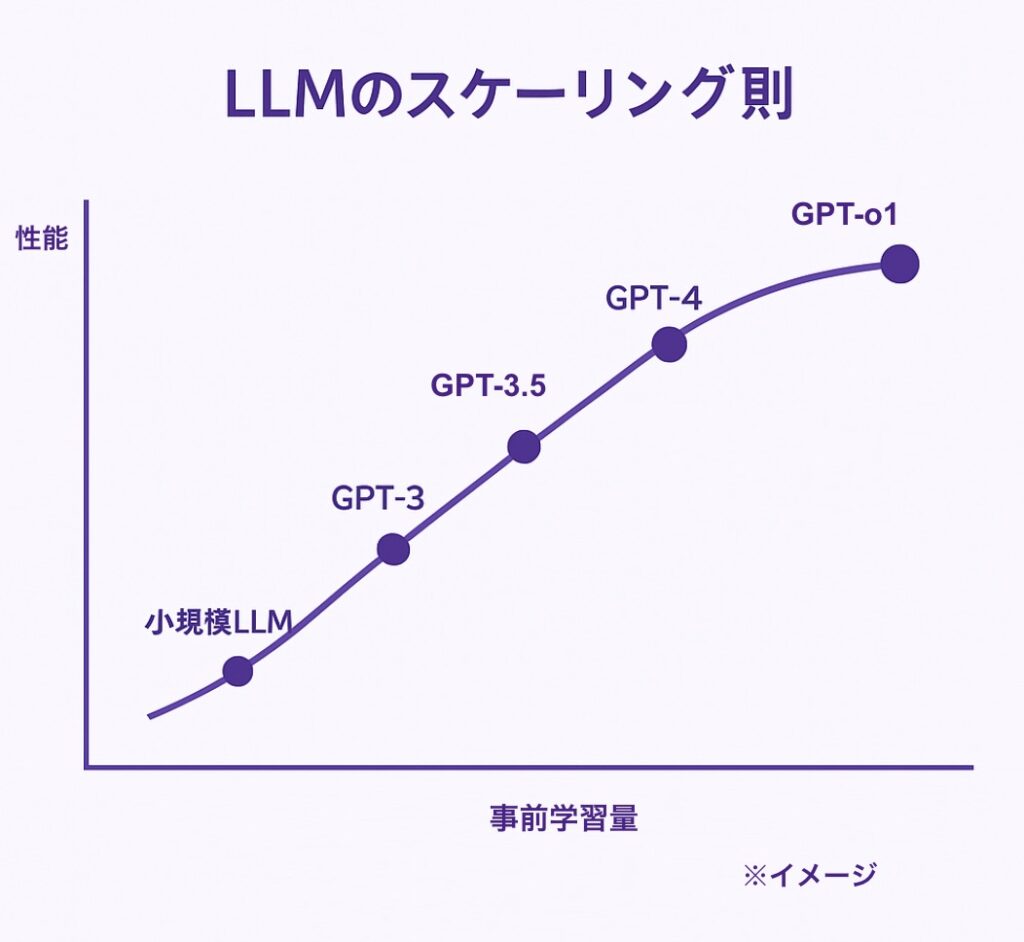
利用可能なデータの上限に到達するから2026年では進化が止まるという「2026年問題」と言う言葉があるくらい、すでに世の中の情報を取り込んでいます。
こうした前提を踏まえると、今の賢いLLMに自社名を覚えてもらうためには、
- LLMが特にどこから情報を学習しているのかを知る
- その学習元のプラットフォームで、自社がアピールしたいトピックと、自社名・ブランド名の関連性が高いことを、AIに分かってもらう
ということが本質になります。
カットオフも把握したい
それから、「カットオフ」という概念も知っておきましょう。
LLMには「カットオフ」という、学習データの締め切り日みたいなものがあります。
例えば、「GPT-3.5」は2022年1月までの情報、「GPT-4o」は2024年6月までの情報で学習されています。
つまり、それ以降に新しくできた会社やサービスの情報は、Web検索機能(RAG)を使わない限り、AIは知らない、ということになります。
なので、AIの学習締め切り(カットオフ)までに、Web上に情報が出ていれば、Web検索なしのLLMでも名前を出してもらえる可能性がある、ということです。
LLMはどこから事前学習しているのか?
では、そのLLMは一体どこから情報を学習しているんでしょうか? ChatGPTはどこから学習しているんだ、ということを知るのが大事です。
LLMの学習データは膨大かつ高品質である必要がある
高性能なAIを作るには、ものすごく大量のデータが必要です。 でも、ただ量が多ければいいわけじゃなくて、データの質も重要です。嘘ばっかりの情報で学習させたくないですよね。
だから、基本的にはインターネット上のWebサイトや、書籍などが学習データとして使われますが、そのあとで質の低いデータを取り除く「スクリーニング」という作業が行われます。
このスクリーニングを通過するような、質の高いメディアに情報が載っていないと、LLMOには繋がりにくいんです。
例えば、Wikipedia。Wikipediaは皆さん「誰でも書けるから意味ないだろ!」みたいに言うのですが、誰かが変な情報を書き込んでも、すぐに修正されたり消されたりしますよね。だから情報源として信頼性が高いとGoogleやLLMは判断しています。
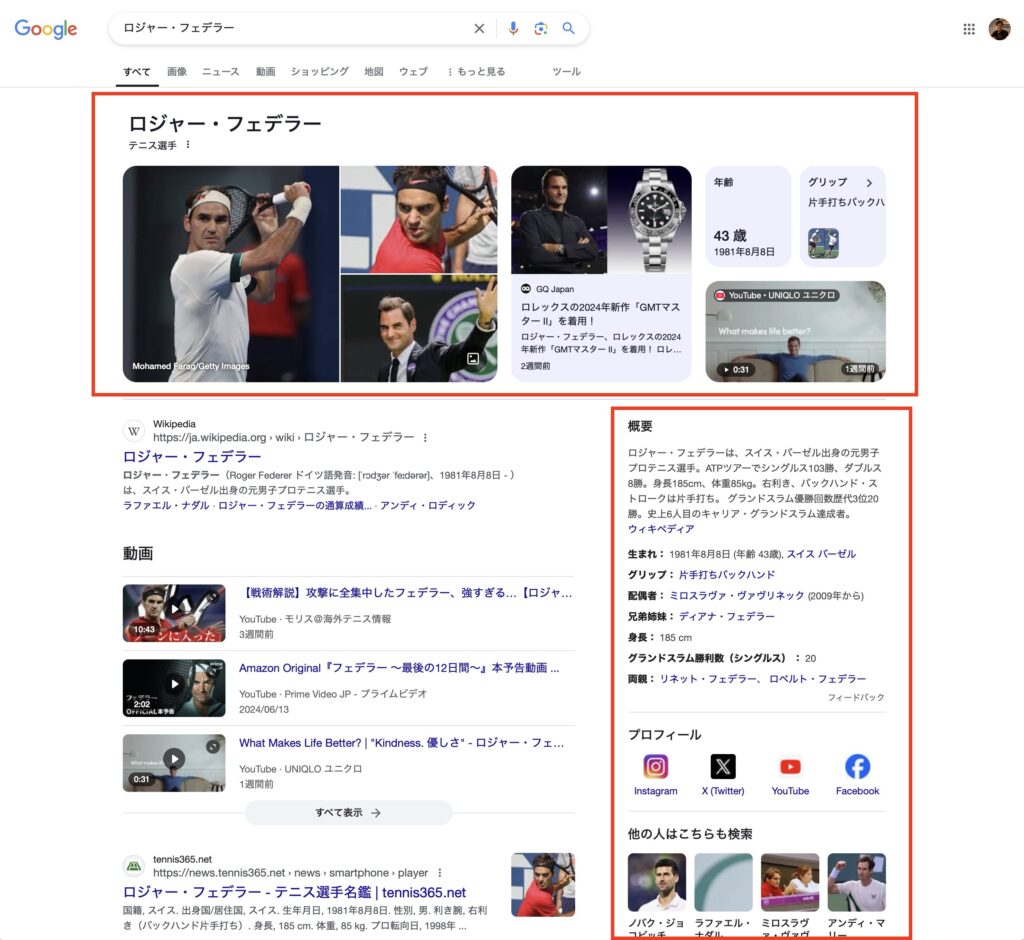
Googleもナレッジパネル(検索結果に出る企業情報ボックス)の情報源として使っているくらいなので、かなり信頼しています。
こういうサイトに載っているテキストは「高品質なテキスト」と言えます。 逆に、スパムサイトみたいなものは「低品質なテキスト」として扱われます。
書籍も質はいいんですが、著作権の問題もあって、Webサイトほど大量には使えません。 あとは、ChatGPTなどはチャットAIなので、会話データなんかも事前学習しています。
Webページの学習についても、文法がめちゃくちゃだったり、句読点が多すぎたり、文章中の単語数や文字数が異常だったりするサイトは、低品質として除外される可能性があります。攻撃的な言葉や卑猥な言葉も同様です。
学習元の一つはCommon Crawl
ちなみに、GPT-3の場合は、「Common Crawl(コモンクロール)」という、インターネット上のWebページを大量に収集しているプロジェクトのデータなどが、主な情報源になっていました。
ただ、 ChatGPTの開発元は、集めたデータをそのまま使うんじゃなくて、先ほど言ったみたいに、品質チェックのスクリーニングを行っています。信頼できるサイト(書籍やWikipediaなど)と似ているか、とか、重複する内容は削除する、とかですね。
自社のブログなどをCommon Crawlに収集してもらうなら、クローラー(情報収集ロボット)がサイトに来るのを拒否しない設定にすることが一つ(robots.txtでブロックしていないか、特にいじっている方以外は大丈夫だと思います)。
サイト内の内部リンクを整理して、検索エンジンにページインデックスしてもらいやすくすることが前提になります。
h3:LLM+RAG(Web検索あり)にはどう対応するか
さて、次はWeb検索機能付きのLLM、つまり「RAG」への対応についてです。
さっきお話ししたように、LLMには「カットオフ」があるので、最新の情報は知りません。これが弱点です。
そこで登場するのが「RAG(ラグ)」、検索拡張という技術です。 AIが外部のデータベース、主にインターネット上のWebページなどを参照して、最新の情報や、LLMの事前学習データにない情報も回答できるようになります。
ChatGPTの検索機能(GPT search)も、このRAGの一種です。
で、LLMOという観点で見ると、このRAGでAIが参照するデータベースとして使われるのが、ずばり、GoogleやBingの「検索結果(SERPs)」なんです。
そのため、RAGに対応するということは、結局のところ、既存のSEOが重要になってくる、ということです。
LLMOの第一歩として、まずはGoogleやBingの検索順位を上げておくことが必須、と言ってもいいでしょう。
RAGの仕組みをざっくり言うと、事前に情報を整理しておく「インデックス」というものが必要なんですが、AI検索においては、このインデックスの役割を、ある意味SEOが担っているイメージですね。
本質的なLLMOのまとめ
ここまで、LLMの仕組みや種類についてお話ししてきました。 では、具体的にどうすればLLMO、つまりAIに自社名を覚えてもらい、出してもらえるようになるのか、本質的なポイントをまとめます。
関連トピックでの自社の言及を増やす
まず一番大事なのは、「自社がポジションを取りたいトピック(分野)」において、「自社名やブランド名」がWeb上でたくさん言及される(サイテーションされる)状況を作ることです。
AIは、どの言葉とどの言葉が関連深いかを学習しています。なので、「この分野といえば、この会社だよね」とAIに認識させることが重要となります。
我々がご提案できるベストなソリューションとしては、エンティティのブランディングをインタビューメディア掲載によって実現できる”VisionaryVoices“というメディアがあります。実際に日本語版のAI モードにも高確率で引用されており、自信を持っておすすめできます。
自社サイトだけでなく、他社メディアでの露出も重要
ここでポイントなのが、自社のWebサイトやブログだけ頑張って更新していても、AIから見たら「1つのサイトでしか言及されてないな」ということになります。
でも、他の会社のメディアやニュースサイト、ブログなど、色々なところで自社について取り上げてもらえれば、「お、この会社、この分野でいろんなサイトから言及されてるぞ。重要なのかも?」とAIが認識しやすくなるはずです。
自社メディアを頑張るのが従来のSEOだとすると、他社メディアも含めて、Web上での露出を増やし、「専門分野」と「自社名・ブランド名」の結びつきの強さをAIに示すのが、LLMOと言えるかもしれません。
そう考えると、ただ自社ブログを更新するだけじゃなくて、
- プレスリリースを配信する
- 業界メディアに記事を寄稿したり、監修したりする
- イベントに登壇する
といった、広報・PR活動までが重要になってきます。
しかも、ただプレスリリースを出すだけじゃなくて、それが他のメディアに取り上げてもらえるような、業界にとってインパクトのあるネタ作りが必要です。
これは、SEO担当者一人でできることではありません。会社全体がチームとなって、世の中に価値のある事業を生み出し、それを効果的に発信していく広報力まで求められる、ということです。
実はこれって、既存のSEOでも、うまく行っている会社が自然とやっていたことなんですよね。それがLLMOの時代になると、より小手先のテクニックではごまかせない、本質的な取り組みが重要になる、ということです。
実際に、私たちが支援している企業さんで、SEOで主要なキーワードで軒並み1位を取っていて、さらに広報活動にも力を入れて、業界で先進的な取り組みや事例をどんどん発信している会社があります。
その会社について、AI検索サービス(PerplexityやGemini)で「(その業種)でおすすめの会社は?」って聞いてみたら、あるサービスでは1番目に、別のサービスでも2番目に名前が出てきたんです。
これは、もうすでにLLMOに成功している、と言える事例ですよね。
特に、その会社は業界での「実績」や「専門性」(専門家がいること、長い歴史があることなど)を、しっかりPRできていました。それが、他のメディアからの紹介や、質の高い被リンクにつながっていたんです。
つまり、「実態」をちゃんと作った上で、SEOと広報の両方を頑張る。これが真のLLMO対策ではないでしょうか。
ちなみに、その会社のサイトは「llms.txt」みたいな特別な設定は入れていません。小手先のテクニックよりも、もっと大事な本質がある、ということだと思います。
ちゃんと業界にインパクトのあるサービスを作り、それを人々に届ける活動(SEO + 広報)が、結果的にLLMOにも繋がるはずです。
信頼性のあるメディアに載ること
さっき、他社メディアに載ることが大事、と言いましたが、どんなメディアでもいいわけではありません。
LLMが学習データとして使うサイトも選別されますし、RAG(Web検索)で情報を引っ張ってくる際にも、信頼性が低いサイトは使われにくい傾向があります。
なので、やはり信頼性の高いメディア、例えば有名なニュースサイトや業界専門誌、公的機関のサイトなどに掲載される方が、効果は高いと考えられます。
ちなみに、ChatGPTのWeb検索機能(RAG)を見ていると、YouTubeの解説動画なんかは引用されることがあるんですが、X(旧Twitter)の投稿はあまり引用されない印象です。なので、LLMOという観点では、X・Facebookの優先順位は低いかもしれません。
自社メディアの信頼性を向上させる
そしてもちろん、自社メディアの情報もAIに学習してほしいですよね。そのためには、自社メディア自体の信頼性を高めていくことが重要です。
- ちゃんと法人として運営していることを見せる
- 会社概要や運営者情報、記事の著者情報をしっかり記載する
- 業界内で関連性が高く、評価されているサイトから言及される(サイテーション)
こうした地道な活動が、自社メディアの信頼性を高め、LLMOにも繋がっていきます。
SEOでも上位表示を取る
最後に、やはりこれです。RAG(Web検索)ではGoogleやBingの検索結果が使われるので、既存のSEO対策は引き続き非常に重要です。
ある調査では、ChatGPTのWeb検索が引用するWebサイトの多くは、Bing検索の上位20件、特にトップ10に入っているページだ、というデータもあります。
Googleでの順位はGoogleのAIモードに、Bingでの順位はChatGPTのRAG対策になると言えます。
ただし、注意点として、たとえBingで上位表示されていても、サイト自体の信頼性が低いと、ChatGPTの回答には使われにくい傾向が見られます。
ChatGPTも、権威のあるニュースサイトや公式サイト、専門性の高いブログなど、「オリジナルで高品質なコンテンツ」を重視する、と述べているのがBingでは個人サイトが上位にいてもChatGPTの回答では出づらいギャップの答えでしょう。
まとめ
今回は「LLMOで自社名を出すには?」というテーマで、どういう意識でメディアを運用していけばいいのか、その考え方の本質について解説しました。
このLLMOという領域は、本当に最先端で、私自身も日々情報を追いかけ、研究しています。
今後、より具体的な施策や、また違った視点での考え方などがまとまってきたら、続報として記事を出していく予定です。
また、アネマでは、今回ご紹介したようなLLMOの視点も含めたSEOコンサルティングや運用支援を、企業様向けに行っています。
「自社のSEO方針がなかなか決まらない」 「記事を書きたいけど、社内にリソースがない」 「AIを使って記事作成を効率化したいけど、品質は落としたくない」
といったお悩みやご要望にお応えしています。 ご興味のある方は、ぜひお問い合わせください。
» SEOの分析・戦略についてアネマに相談する